notas-y-apuntes
Introduccion al Analisis de datos con Python
¿En que consiste el curso?
Taller introductorio al analisis de datos, en el cual se trabajará con el lenguaje Python, considerando su potencial y usos para el analisis de datos. El taller considera manipulacion de datos, visualizacion y modelacion, lo cual permitirá a los estudiantes manipular, analizar y presentar datos de acuerdo a distintas necesidades
Unidades de aprendizaje
- Análisis de datos: codificar programa en Python, a traves de operadores matematicos y metodos elementales, para generar estadisticas basicas a partir de la informacion cargada.
- Visualizacion de datos: generar graficos utilizando Seaborn, utilizando parametros de acuerdo a necesidades y acorde a la data.
- Modelacion: codificar modelo de regresion lineal generando un grafico regplot para entender/interpretar los resultados obtenidos.
Plataforma y software
¿Por que es importante aprender analisis de datos?
Porque dia a dia se generan millones de datos cada segundo y el desafio para los profesionales es sacrale provecho a toda la informacion que se genera. Se puede comenzar con un analisis de grafico simple, generar reporteria automatica, chatbots, sistemas de recomendacion como netflix o spotify.
Herraientas de analisis de datos:
Dentro de las herramientas de analisis de datos, existen muchas posibilidades, pero nosorros nos enfocaremos en usar el lenguaje Python.
¿Que aprenderemos?
Vamos a cargar y manipular datos, vamos a generar operaciones simples, como suma, filtros, agruparemos , vamos a aprender sobre visualizaciones con graficos.
Indicaciones
- Descargar el archivo Data_analisis.zip provisto por Desafio LATAM, el el computador y descomprimirlo, aqui encontraremos el archivo con ña extemsion .ipynb que contiene el .csv con el que se trabajará en el taller.
- Inicia una sesion en google, luego ingresa a https://colab.research.google.com/.
- Haz click en Archivo :arrow_right: Subir cuaderno
Glosario
- Acumulador: Variable creada usualmente dentro de una iteración, que va acumulando la suma sucesiva de un dato variable.
- Algoritmo: Serie finita de pasos para resolver un problema.
- Buenas prácticas de programación: Consiste en todo aquello que tenga relación con optimizar el código; desde su comprensión al leerlo, hasta el mejoramiento de su funcionamiento. Existen prácticas de programación generales, así como algunas más específicas dependiendo de cada lenguaje. Se considera parte de las buenas prácticas seguir las convenciones establecidas para cada lenguaje.
- Bug: En programación, corresponde a un error o falla en nuestro programa que genera un resultado o comportamiento inesperado.
- Clase: Modelo que define las propiedades y métodos que tendrá un determinado objeto.
- Contador: Variable que, dentro de una iteración, va aumentando su valor de 1 en 1.
- Debug: Corresponde al proceso de buscar y resolver conflictos o ‘bugs’ en nuestros programas. Para ello existen herramientas especializadas.
- De código abierto: Término con el que se conoce al software distribuido y desarrollado libremente con licencias que permiten su implementación, modificación y distribución.
- Documentación/Documentar el código: La documentación corresponde a líneas dentro del código que no se ejecutan, y que explican qué está haciendo el código escrito en esa sección, notas relevantes, ejemplos, etc. Documentar el código es un ejemplo de una buena práctica de programación. Además de escribir la documentación en el código mismo del programa, usualmente es posible también acceder a ella a través de páginas web, para el caso de un lenguaje completo, o de una librería específica.
- Editor de texto: Software que permite crear y modificar archivos compuestos únicamente por textos sin formato, conocidos comúnmente como archivos de texto o “texto plano”.
- Framework: Conjunto de herramientas para un propósito. Estas herramientas permiten estandarizar la forma en que se construye el programa.
- Función: Bloques de código reutilizables que permiten crear soluciones modulares. Las funciones en Python, están definidas por sí mismas y no pertenecen a ninguna clase.
- IDE (Integrated Desktop Environment): Corresponde a un software que contiene un set de herramientas para desarrollo de software. Un IDE normalmente contiene un editor de texto, compilador o intérprete y herramientas de debug, entre otras funcionalidades.
- Indentación: También conocido como sangrado. Consiste en espacios vacíos que se dan antes de una instrucción para especificar que está dentro de un contexto.
- Imprimir en pantalla: Definir en nuestro código, de manera explícita, que un dato debe ser mostrado en la pantalla a través de instrucciones del tipo print.
- Importar: Se refiere a traer código externo al código que se está escribiendo. Esto se logra mediante la instrucción import. Se pueden importar librerías, o archivos propios de extensión “.py”.
- Interpolación: Acción que permite insertar el valor de una variable dentro de una cadena de texto.
- Kernel de Python: Corresponde al servidor levantado en el computador que permitirá ejecutar Python. Se ejecuta al escribir la instrucción python desde la terminal. Otro kernel muy utilizado es IPython, y se ejecuta desde la terminal con la instrucción ipython. El kernel es también el que hace posible hacer bloques de código en Jupyter Notebook.
- Lenguaje de programación: Un lenguaje de programación es un lenguaje diseñado para describir el conjunto de acciones que un computador debe ejecutar. Por lo tanto, un lenguaje de programación es un modo práctico para que los seres humanos puedan dar instrucciones a un equipo.
- Librería: Las “bibliotecas” (su origen es la palabra “library” en inglés, pero es común utilizar “librería”) corresponde a un conjunto de funciones orientadas a un objetivo específico (por ejemplo, generar gráficos), estructuradas en uno o más archivos externos al programa principal que se está escribiendo. Para utilizar una librería, ésta se debe importar al código. Normalmente, son de código abierto, y se puede acceder a ellas, o descargarlas, desde un gestor de paquetes, el cual varía para cada lenguaje.
- Llamar: Se refiere a escribir el nombre de una variable, para obtener su valor, o el de una función, para utilizarla. En el caso de llamar a una función, se debe agregar paréntesis () al final del nombre, y agregar parámetros de ser necesario.
- Método: Los métodos son acciones o funciones que puede realizar un objeto. Python ofrece un conjunto de métodos ya creados previamente. Estos métodos dependen del tipo de objeto con el que estemos trabajando. Un método es parte de una clase, es decir, es parte de la funcionalidad que le damos a un objeto. Por tanto, siempre va a estar asociado a un objeto. Para utilizarse deben ser “llamados”.
- Métodos nativos/Built-in methods: Corresponden a métodos integrados en el lenguaje mismo. Para utilizarlos, no es necesario crear un objeto; pueden ser llamados directamente.
- Objeto: Unidad o elemento que corresponde a la instancia de una clase. El objeto tiene propiedades y métodos asociados, y según ellos, se puede realizar distintas operaciones sobre el objeto.
- Paradigma de programación: Representa un enfoque particular para diseñar soluciones utilizando un lenguaje de programación. En el caso de Python, se utiliza el Paradigma Orientado a Objetos.
- Programa: Un programa informático o programa de computadora es una secuencia de instrucciones, escritas para realizar una tarea específica en una computadora.
- Prompt: Se llama prompt al carácter o conjunto de caracteres que se muestran en un terminal para indicar que está a la espera de órdenes.
- Refactorización (refactoring): Corresponde al proceso de reestructurar un código fuente, alterando su estructura interna sin modificar su comportamiento. Normalmente se aplica para optimizar el funcionamiento del código y/o facilitar su lectura por parte del programador.
- Script: Es un programa usualmente simple que se puede ejecutar desde el terminal.
- Terminal: También se le llama “Consola”. Se refiere a la “Línea de comandos” de nuestro sistema operativo, por medio de la cual se pueden ejecutar distintas instrucciones, o comandos, para distintos fines. También se le conoce como “CLI”, por sus siglas en inglés (“CommandLineInterface”).
- Tipo de dato: O tipo de objeto. Corresponde a la naturaleza o propiedad de un objeto. Los tipos de datos más utilizados son integer, float, string y boolean.
- Variable: Contenedor de un valor o del resultado de una expresión. Su valor puede cambiar a lo largo del código.
Analisis de datos
Ahora que estamos en contexto, sabemos lo elemental de programacion, la sintaxis de python, las variables, las librerias, etc. Lo primero que haremos es realizar un comentario. Estaremos trabajando en el archivo Data Analisis.ipynb de Google Colab Python cuando sabe que hay un comentario, lo ignora, solo se mantienen en codigo
Los lenguajes de programación cuentan con una serie de herramientas básicas incorporadas, como las que acabamos de ver. Sin embargo, existen expansiones de funcionalidades que han sido derrolladas previamente de modo de ahorrarnos trabajo y hacer todo más simple.
Dependencias
Estas “expansiones” se llaman bibliotecas o librerías
#Importemos algunas de las librerías más clásicas para el manejo de datos en Python
#Pandas es la librería básica para la manipulación y análisis de datos
import pandas as pd
#Numpy es la biblioteca para crear vectores y matrices, además de un conjunto grande de funciones matemáticas
import numpy as np
#Seaborn es una librería que usamos para graficar
import seaborn as sns
#Statsmodels es la biblioteca para realizar modelos
import statsmodels.formula.api as smf
Carga de datos
Pandas es la libreria que nos permitira la carga y analisis de datos
Ahora, ¡manos a la obra!
Trabajaremos con el dataset ‘nations’, el cual contiene información sobre diferentes atributos de desarrollo humano en 194 países, recolectados por las Naciones Unidas.
- Contiene información a nivel mundial sobre demografía:
country: País.region: Continente del país.gdp: Producto Interno Bruto per cápita, precios 2005.school: Promedio años de escolaridad.adfert: Fertilidad adolescente (Nacimientos 1:1000 en mujeres entre 15 y 19).chldmort: Probabilidad de muerte antes de los 5 años por cada 1000.life: Esperanza de vida al nacer.pop: Población total.urban: Porcentaje de población urbana.femlab: Tasa entre hombres y mujeres en el mercado laboral.literacy: Tasa de alfabetismo.co2: Toneladas de Co2 emitidas per cápita.gini: Coeficiente de desigualdad del ingreso.
import pandas as pd
df_nations = pd.read_csv("https://raw.githubusercontent.com/DireccionAcademicaADL/Nations-DB/main/nations.csv", encoding="ISO-8859-1")
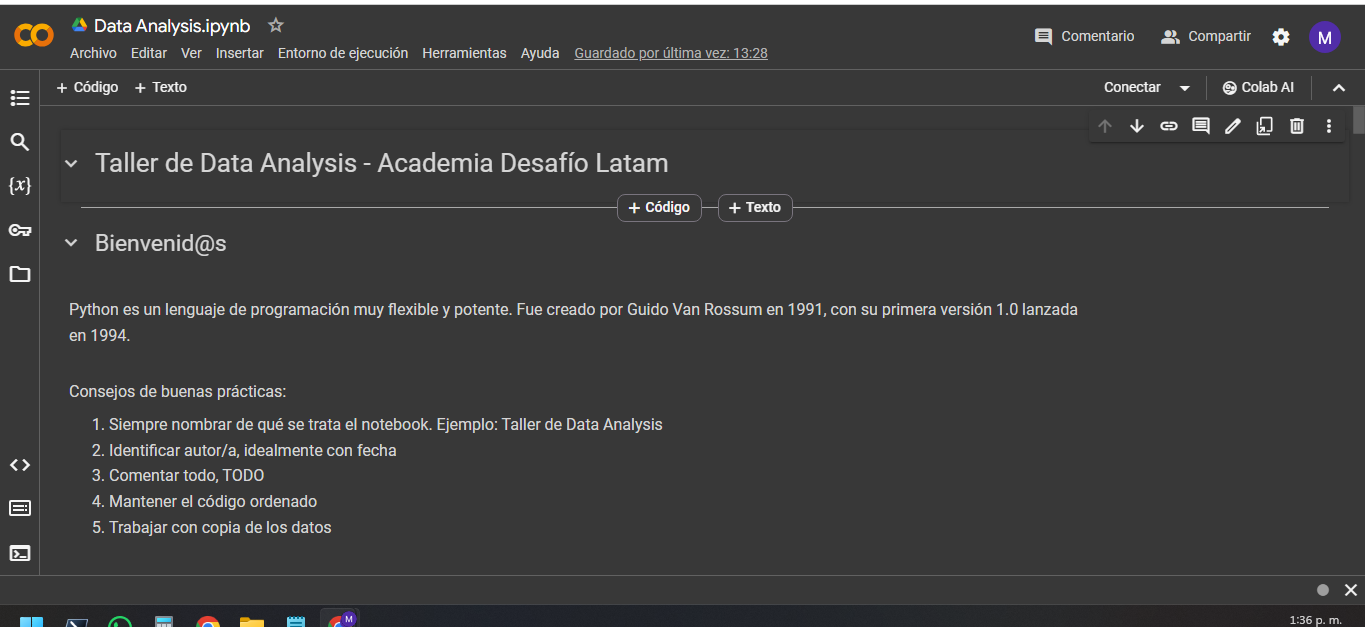
print(df_nations)
Python nos regresa una muestra de nuestro data set
Metodos de pandas
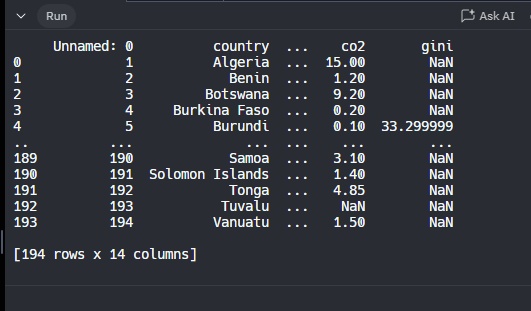
HEAD()
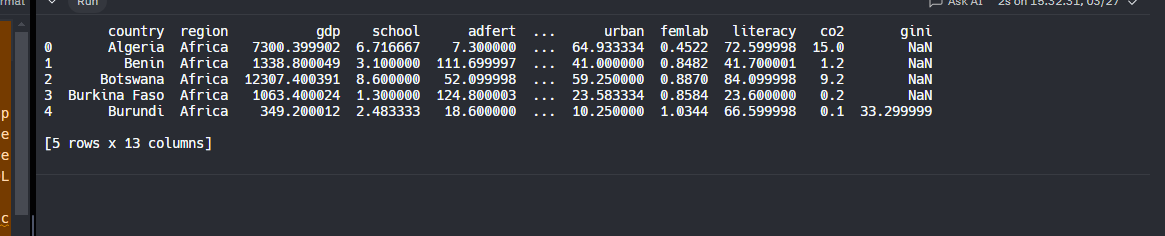
Uno de los metodos mas utilizados y que nos va a servir mucho para realizar analisis de datos es el metodo de head, este metodo nos mostrará las primeras 5 observaciones de nuestro data set
import pandas as pd
df_nations = pd.read_csv("https://raw.githubusercontent.com/DireccionAcademicaADL/Nations-DB/main/nations.csv", encoding="ISO-8859-1")
print(df_nations.head())
Nos regresa esto:
TAIL()
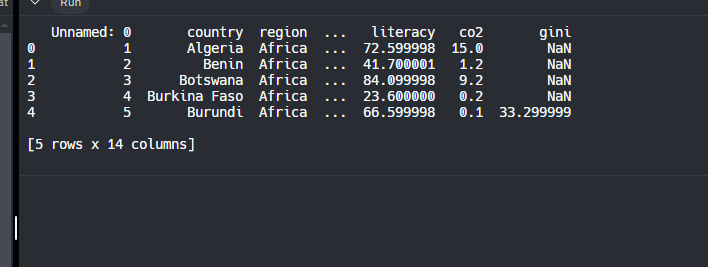
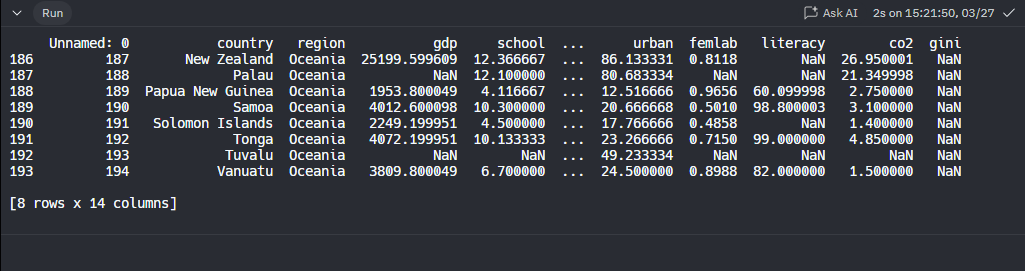
El metodo tail() nos regresa las ultimos 5 entradas de la tabla
import pandas as pd
df_nations = pd.read_csv("https://raw.githubusercontent.com/DireccionAcademicaADL/Nations-DB/main/nations.csv", encoding="ISO-8859-1")
print(df_nations.tail())
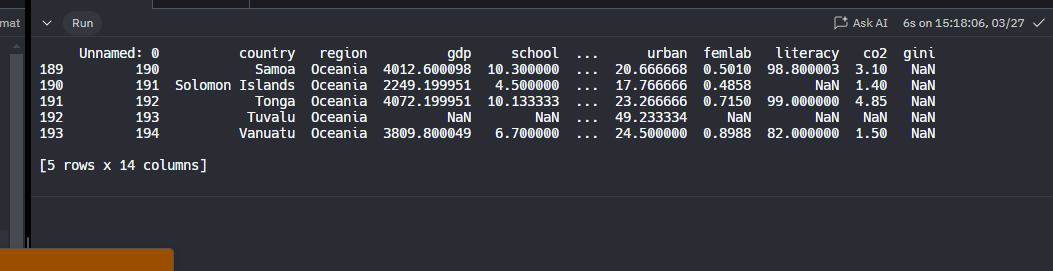
Si le enviamos un paramentro en tail() nos traera la cantidad que le pidamos en ese parametro
import pandas as pd
df_nations = pd.read_csv("https://raw.githubusercontent.com/DireccionAcademicaADL/Nations-DB/main/nations.csv", encoding="ISO-8859-1")
print(df_nations.tail(8))
DROP()
nos ayuda a eliminar columnas de nuestro data set
En nuestro caso vamos a eliminar una columna llamada UNNAMED: 0para que nuestro data set tenga las columnas necesarias
import pandas as pd
df_nations = pd.read_csv("https://raw.githubusercontent.com/DireccionAcademicaADL/Nations-DB/main/nations.csv", encoding="ISO-8859-1")
df_nations.drop(columns=["Unnamed: 0"], inplace=True) # Eliminar la columna "Unnamed: 0" del DataFrame original
print(df_nations.head()) # Imprimir las primeras filas del DataFrame modificado
.columns
Nos regresa una lista de los nombres de las lulumnas que tiene nuestro data set
import pandas as pd
df_nations = pd.read_csv("https://raw.githubusercontent.com/DireccionAcademicaADL/Nations-DB/main/nations.csv", encoding="ISO-8859-1")
df_nations.drop(columns=["Unnamed: 0"], inplace=True)
print(df_nations.columns)
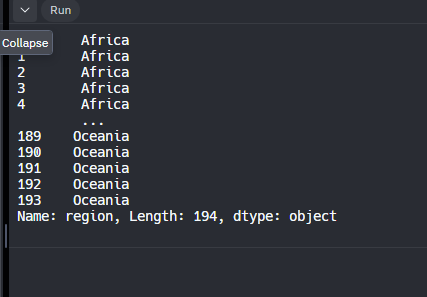
Si queremos ver una columna en especifico la colocamos entre corchetes
import pandas as pd
df_nations = pd.read_csv("https://raw.githubusercontent.com/DireccionAcademicaADL/Nations-DB/main/nations.csv", encoding="ISO-8859-1")
df_nations.drop(columns=["Unnamed: 0"], inplace=True)
print(df_nations['region'])
Crear una columna nueva
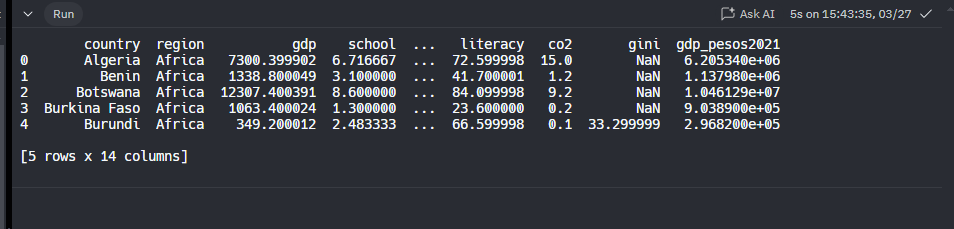
Otra cosa que podemos hacer con el data frame de pandas es crear nuevas columnas. Se crea directamente, y como ejemplo, vamos a ver como crear la columna gdp en pesos del año 2021
import pandas as pd
df_nations = pd.read_csv("https://raw.githubusercontent.com/DireccionAcademicaADL/Nations-DB/main/nations.csv", encoding="ISO-8859-1")
df_nations.drop(columns=["Unnamed: 0"], inplace=True)
df_nations["gdp_pesos2021"] = df_nations["gdp"]*850
print(df_nations.head())
Analisis descriptivo
Para continuar con nuestro análisis de los datos, vamos a plantear una serie de interrogantes que guiarán el taller:
- ¿Qué tipos de atributos nos encontramos en el dataset?
- ¿Cuántos datos tenemos en cada región?
- ¿Cuántos países tienen índices de CO_2 mayores que el promedio?
- ¿Que se puede decir del alfabetismo en áfrica o europa?
Metodo .info()
import pandas as pd
df_nations = pd.read_csv("https://raw.githubusercontent.com/DireccionAcademicaADL/Nations-DB/main/nations.csv", encoding="ISO-8859-1")
df_nations.drop(columns=["Unnamed: 0"], inplace=True)
df_nations["gdp_pesos2021"] = df_nations["gdp"]*850
print(df_nations.info())
Nos regresa una tabla que nos indica cuales son los nombres de las columnas, cuantas celdas de esas columnas no tienen valor NULL y el tipo de dato
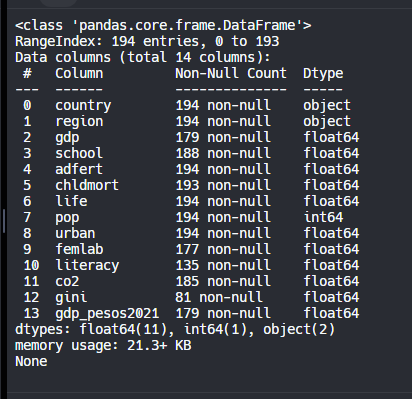
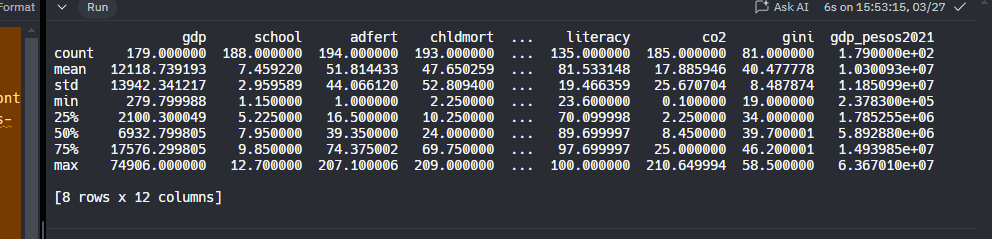
Metodo describe()
Otro método muy útil cuando estamos explorando los datos, es describe(); el cuál calcula estadísticas básicas de los atributos numéricos (float o int), dejando fuera los atributos categóricos o cualitativos.
import pandas as pd
df_nations = pd.read_csv("https://raw.githubusercontent.com/DireccionAcademicaADL/Nations-DB/main/nations.csv", encoding="ISO-8859-1")
df_nations.drop(columns=["Unnamed: 0"], inplace=True)
df_nations["gdp_pesos2021"] = df_nations["gdp"]*850
print(df_nations.describe())
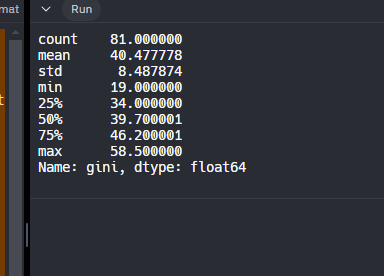
Tambien podemos llamarlo para una sola columna
import pandas as pd
df_nations = pd.read_csv("https://raw.githubusercontent.com/DireccionAcademicaADL/Nations-DB/main/nations.csv", encoding="ISO-8859-1")
df_nations.drop(columns=["Unnamed: 0"], inplace=True)
df_nations["gdp_pesos2021"] = df_nations["gdp"]*850
print(df_nations['gini'].describe())
Metodo .mean()
Podemos traer el promedio
import pandas as pd
df_nations = pd.read_csv("https://raw.githubusercontent.com/DireccionAcademicaADL/Nations-DB/main/nations.csv", encoding="ISO-8859-1")
df_nations.drop(columns=["Unnamed: 0"], inplace=True)
df_nations["gdp_pesos2021"] = df_nations["gdp"]*850
print(df_nations['gini'].mean())
40.4777778107443
Metodo .count()
import pandas as pd
df_nations = pd.read_csv("https://raw.githubusercontent.com/DireccionAcademicaADL/Nations-DB/main/nations.csv", encoding="ISO-8859-1")
df_nations.drop(columns=["Unnamed: 0"], inplace=True)
df_nations["gdp_pesos2021"] = df_nations["gdp"]*850
print(df_nations['gini'].count())
81
Metodo .groupby()
import pandas as pd
df_nations = pd.read_csv("https://raw.githubusercontent.com/DireccionAcademicaADL/Nations-DB/main/nations.csv", encoding="ISO-8859-1")
df_nations.drop(columns=["Unnamed: 0"], inplace=True)
df_nations["gdp_pesos2021"] = df_nations["gdp"]*850
print(df_nations.groupby(["region"])[["country"]].count())
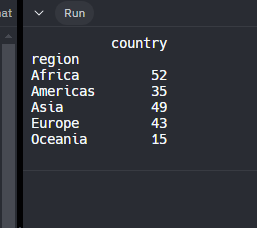
Recordando que “Region” son los continentes y “country” los paises, este metodo nos agrupa por region y nos cuenta la cantidad de paises que hay en cada uno
Metodo where()
Este metodo nos regresa las filas que cumplan con una funcion, utilizando la libreria numpy.
Siguiendo con la manipulación de los datos, un método que nos ayuda a recodificar una variable (o crear una nueva a partir de una condición), es el método where(); el cual proviene de la librería numpy y nos permite decidir, a través de una condición, qué va en el lugar de aquellas filas que cumplen la condición, y qué va en el lugar de las filas que no cumplen la condición. La sintáxis correcta de uso sería:
df_nations["variable"] = **np.where**(_Condición_, valor si verdadero, valor si falso)
import pandas as pd
import numpy as np
df_nations = pd.read_csv("https://raw.githubusercontent.com/DireccionAcademicaADL/Nations-DB/main/nations.csv", encoding="ISO-8859-1")
df_nations.drop(columns=["Unnamed: 0"], inplace=True)
df_nations["gdp_pesos2021"] = df_nations["gdp"]*850
df_nations["co2_recodificada"] = np.where(df_nations["co2"]> df_nations["co2"].mean(), 1, 0)
print(df_nations.head())
Aqui nos está regresando los 5 primeros paises, que si tienen emision de CO2 por encima del promedio la columna co2_recodificada tendrá 1 y caso contrario, tendrá 0

Y si queremos saber cuantos son los paises que estan por encima del promedio de emision de CO2 y cuantos nos, podemos utilizar .value_count()
import pandas as pd
import numpy as np
df_nations = pd.read_csv("https://raw.githubusercontent.com/DireccionAcademicaADL/Nations-DB/main/nations.csv", encoding="ISO-8859-1")
df_nations.drop(columns=["Unnamed: 0"], inplace=True)
df_nations["gdp_pesos2021"] = df_nations["gdp"]*850
df_nations["co2_recodificada"] = np.where(df_nations["co2"]> df_nations["co2"].mean(), 1, 0)
print(df_nations["co2_recodificada"].value_counts())
co2_recodificada
0 130
1 64
Name: count, dtype: int64
Y si queremos hacer que nos regrese una respuesta mas elaborada
import pandas as pd
import numpy as np
df_nations = pd.read_csv("https://raw.githubusercontent.com/DireccionAcademicaADL/Nations-DB/main/nations.csv", encoding="ISO-8859-1")
df_nations.drop(columns=["Unnamed: 0"], inplace=True)
df_nations["gdp_pesos2021"] = df_nations["gdp"]*850
df_nations["co2_recodificada"] = np.where(df_nations["co2"]> df_nations["co2"].mean(), 1, 0)
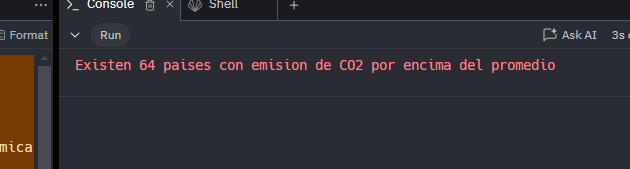
cantidad = df_nations["co2_recodificada"].value_counts()[1]
print("\033[0;31m", f"Existen {cantidad} paises con emision de CO2 por encima del promedio")
Y si l queremos en porcentaje
df_nations["co2_recodificada"].value_counts("%")
0 0.670103
1 0.329897
Name: co2_recodificada, dtype: float64
Filtros
Filtramos solo los paises que pertenezcan a África de esta manera
import pandas as pd
import numpy as np
df_nations = pd.read_csv("https://raw.githubusercontent.com/DireccionAcademicaADL/Nations-DB/main/nations.csv", encoding="ISO-8859-1")
df_nations.drop(columns=["Unnamed: 0"], inplace=True)
df_nations["gdp_pesos2021"] = df_nations["gdp"]*850
df_nations["co2_recodificada"] = np.where(df_nations["co2"]> df_nations["co2"].mean(), 1, 0)
# Filtro por variable "Region"
africaCountries = df_nations[df_nations["region"]=="Africa"]
print(africaCountries)
Para buscar la tasa de alfabetismo en Africa y Europa utilizamos el metodo .mean()
import pandas as pd
import numpy as np
df_nations = pd.read_csv("https://raw.githubusercontent.com/DireccionAcademicaADL/Nations-DB/main/nations.csv", encoding="ISO-8859-1")
df_nations.drop(columns=["Unnamed: 0"], inplace=True)
df_nations["gdp_pesos2021"] = df_nations["gdp"]*850
df_nations["co2_recodificada"] = np.where(df_nations["co2"]> df_nations["co2"].mean(), 1, 0)
# Filtro por variable "Region"
df_africa = df_nations[df_nations["region"]=="Africa"]
alf_africa = df_africa["literacy"].mean()
df_europa =df_nations[df_nations["region"]=="Europe"]
alf_europa = df_europa["literacy"].mean()
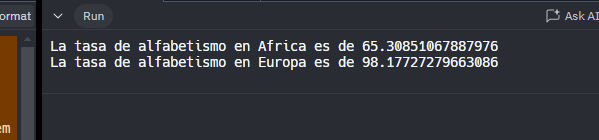
print(f"La tasa de alfabetismo en Africa es de {alf_africa}")
print(f"La tasa de alfabetismo en Europa es de {alf_europa}")
Visualizacion de datos
La visualización gráfica de datos constituye una disciplina en si misma. Existen muchos tipos de datos y utilizar el gráfico correcto, según la necesidad de información y el objetivo a comunicar es clave en este proceso.
 Fuente: Analytics Vidhya
Fuente: Analytics Vidhya
Nota: hasta este punto hemos estado usando replit.com, a partir de ahora usaremos la terminal de comando de Windows (en nuestro caso)
Verificar la version de python en nuestra PC
python --version
Si lo tenemos instalado, nos regresará la version de python en la pc vamos a crear una carpeta y luego nos movemos a esa carpeta
mkdir data-analisis
cd data-analisis
Vamos a necesitar saber que dependencias tenemos instaladas
pip freeze > requirements.txt
Este comando guarda una lista de todas las bibliotecas instaladas en tu entorno virtual en un archivo llamado requirements.txt.
Ahora instalamos las dependencias que necesitamos
pip install pandas numpy seaborn matplotlib --user
Como dijimos al principio
- Pandas es la librería básica para la manipulación y análisis de datos
- Numpy es la biblioteca para crear vectores y matrices, además de un conjunto grande de funciones matemáticas
- Seaborn es una librería que usamos para graficar
- matplotlib lo utilizaremos para crear la grafica y visualizarla.
#Pandas es la librería básica para la manipulación y análisis de datos
import pandas as pd
#Numpy es la biblioteca para crear vectores y matrices, además de un conjunto grande de funciones matemáticas
import numpy as np
#Seaborn es una librería que usamos para graficar
import seaborn as sns
# Importamos matplotlib.pyplot para mostrar el gráfico
import matplotlib.pyplot as plt
# Extraemos la informacionn
df_nations = pd.read_csv("https://raw.githubusercontent.com/DireccionAcademicaADL/Nations-DB/main/nations.csv", encoding="ISO-8859-1")
# Borramos la columna innecesaria ["Unnamed: 0"]
df_nations.drop(columns=["Unnamed: 0"], inplace=True)
# Añadimos una nuevacolumna que calcule el nuevo monto de gdp actuales
df_nations["gdp_pesos2021"] = df_nations["gdp"]*850
# Añadimos una nueva columna que nos indique que paises estan sobre la media en emision de CO2
df_nations["co2_recodificada"] = np.where(df_nations["co2"]> df_nations["co2"].mean(), 1, 0)
# Usamos seaborn para graficar el histograma del índice Gini
sns.displot(df_nations["gini"], kind="hist")
# Mostramos la ventana emergente con el histograma
plt.show()
Ejecutamos el comando python main.py dentro del directorio y nos regresa
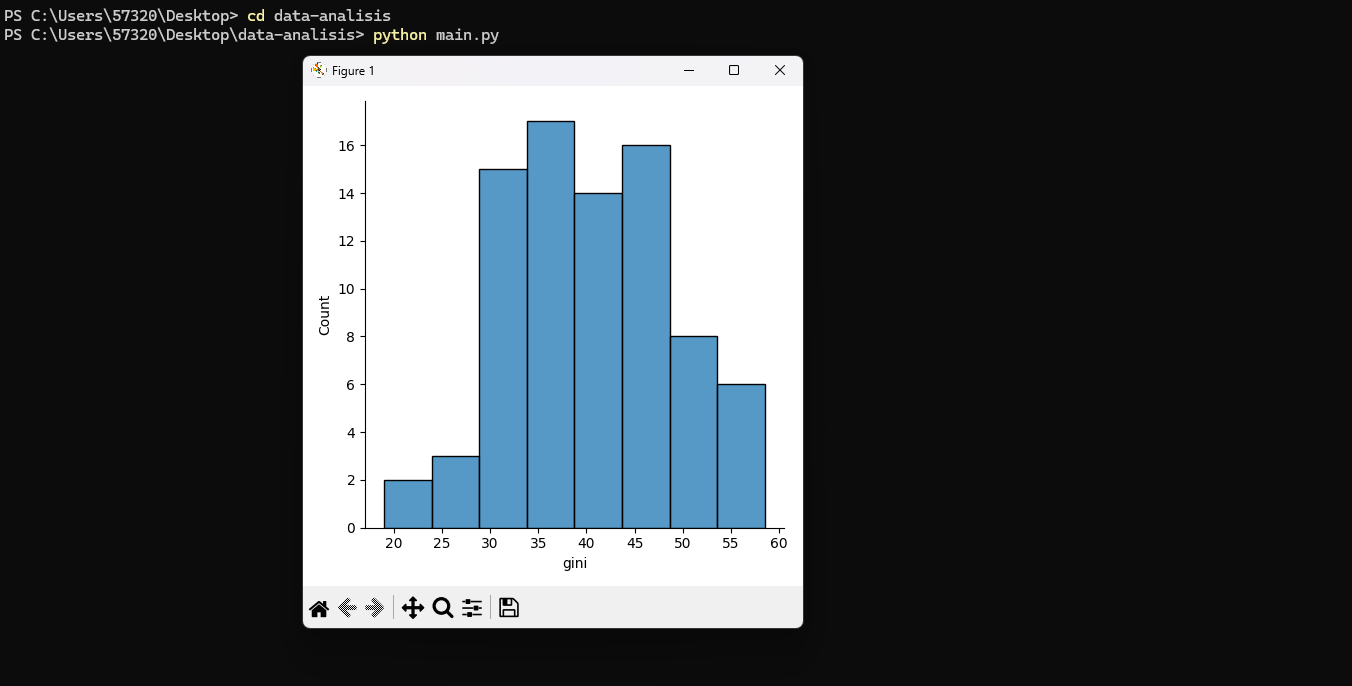
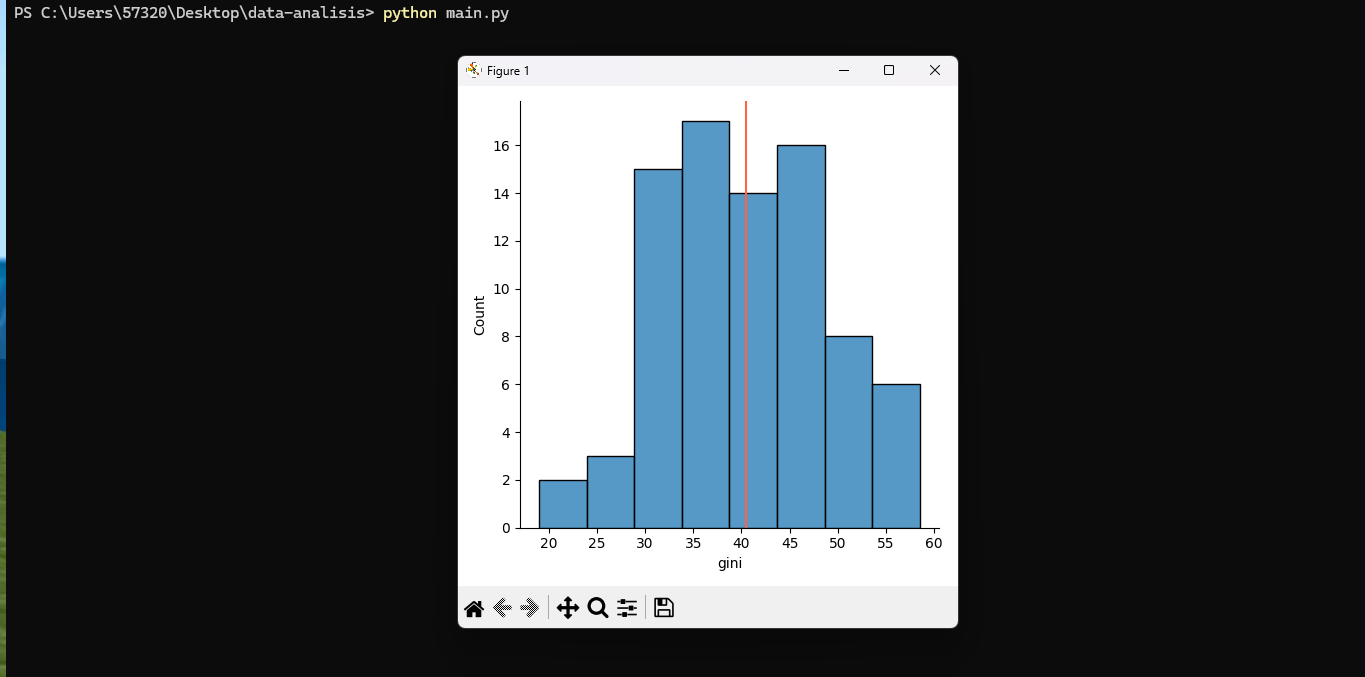
Del gráfico anterior, se desprende que la mayor concentración del índice gini está entre los 30 y 50 puntos, pero sería valioso agregar el valor promedio del gini en nuestra muestra. ¿Cómo hacemos eso?
#Pandas es la librería básica para la manipulación y análisis de datos
import pandas as pd
#Numpy es la biblioteca para crear vectores y matrices, además de un conjunto grande de funciones matemáticas
import numpy as np
#Seaborn es una librería que usamos para graficar
import seaborn as sns
#Statsmodels es la biblioteca para realizar modelos
#import statsmodels.formula.api as smf
# Importamos matplotlib.pyplot para mostrar el gráfico
import matplotlib.pyplot as plt
# Extraemos la informacionn
df_nations = pd.read_csv("https://raw.githubusercontent.com/DireccionAcademicaADL/Nations-DB/main/nations.csv", encoding="ISO-8859-1")
# Borramos la columna innecesaria ["Unnamed: 0"]
df_nations.drop(columns=["Unnamed: 0"], inplace=True)
# Añadimos una nuevacolumna que calcule el nuevo monto de gdp actuales
df_nations["gdp_pesos2021"] = df_nations["gdp"]*850
# Añadimos una nueva columna que nos indique que paises estan sobre la media en emision de CO2
df_nations["co2_recodificada"] = np.where(df_nations["co2"]> df_nations["co2"].mean(), 1, 0)
# Usamos seaborn para graficar el histograma del índice Gini
sns.displot(df_nations["gini"], kind="hist")
# Creamos una linea que muestra el valor promedio de gini
plt.axvline(df_nations["gini"].mean(), color = "tomato")
# Mostramos la ventana emergente con el histograma
plt.show()
Volvemos a ejecutar python main.py y nos regresa:
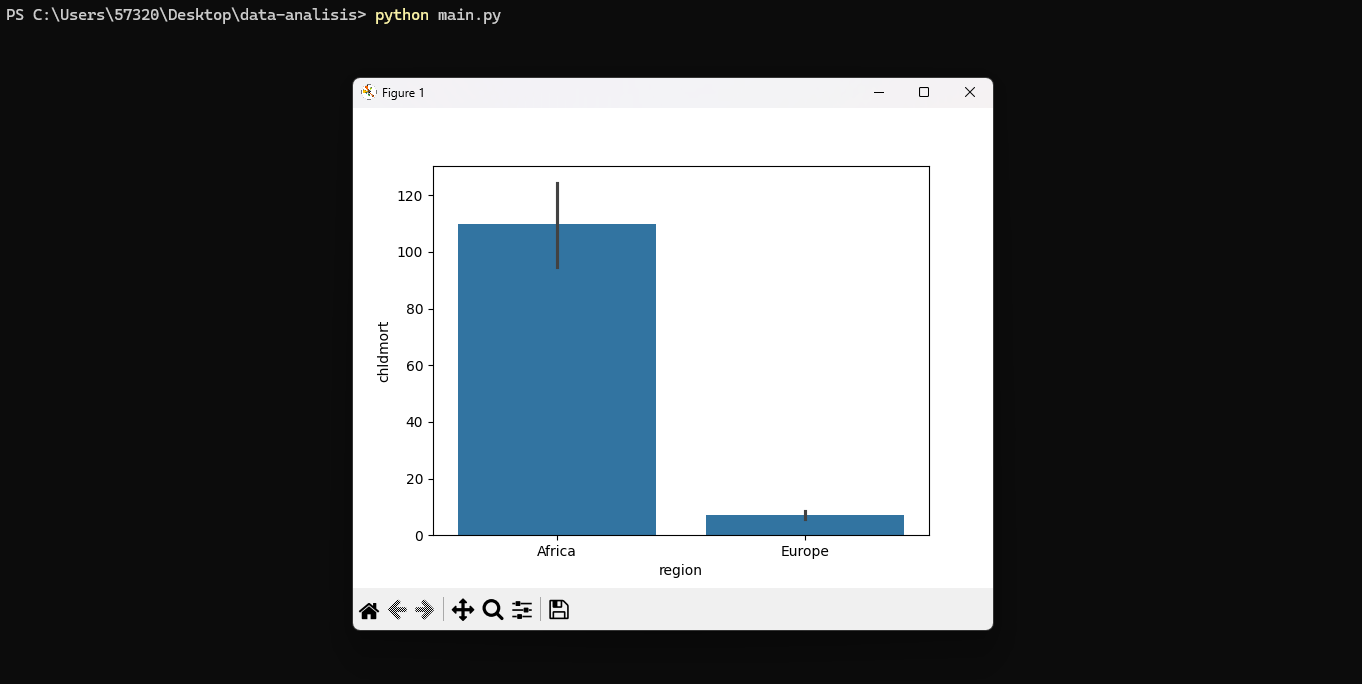
Ahora utilizaremos gráficos de barras para observar comparaciones de comportamiento de regiones versus el resto del mundo.
Ya habíamos creado los filtros de df_africa y df_europa, con esto vamos a comparar la mortalidad infantil.
#Pandas es la librería básica para la manipulación y análisis de datos
import pandas as pd
#Numpy es la biblioteca para crear vectores y matrices, además de un conjunto grande de funciones matemáticas
import numpy as np
#Seaborn es una librería que usamos para graficar
import seaborn as sns
#Statsmodels es la biblioteca para realizar modelos
#import statsmodels.formula.api as smf
# Importamos matplotlib.pyplot para mostrar el gráfico
import matplotlib.pyplot as plt
# Extraemos la informacionn
df_nations = pd.read_csv("https://raw.githubusercontent.com/DireccionAcademicaADL/Nations-DB/main/nations.csv", encoding="ISO-8859-1")
# Borramos la columna innecesaria ["Unnamed: 0"]
df_nations.drop(columns=["Unnamed: 0"], inplace=True)
# Añadimos una nuevacolumna que calcule el nuevo monto de gdp actuales
df_nations["gdp_pesos2021"] = df_nations["gdp"]*850
# Añadimos una nueva columna que nos indique que paises estan sobre la media en emision de CO2
df_nations["co2_recodificada"] = np.where(df_nations["co2"]> df_nations["co2"].mean(), 1, 0)
# Tenemos los filtros df_africa y df_europe
df_africa = df_nations[df_nations["region"]=="Africa"]
df_europa =df_nations[df_nations["region"]=="Europe"]
# Juntamos los dos filtros para cerar una misma tabla
df_euafr = df_nations.loc[df_nations["region"].isin(["Europe","Africa"])]
# Usamos seaborn para graficar el histograma del índice Gini
sns.barplot(data=df_euafr, x="region", y="chldmort")
# Mostramos la ventana emergente con el histograma
plt.show()
Nos regresa
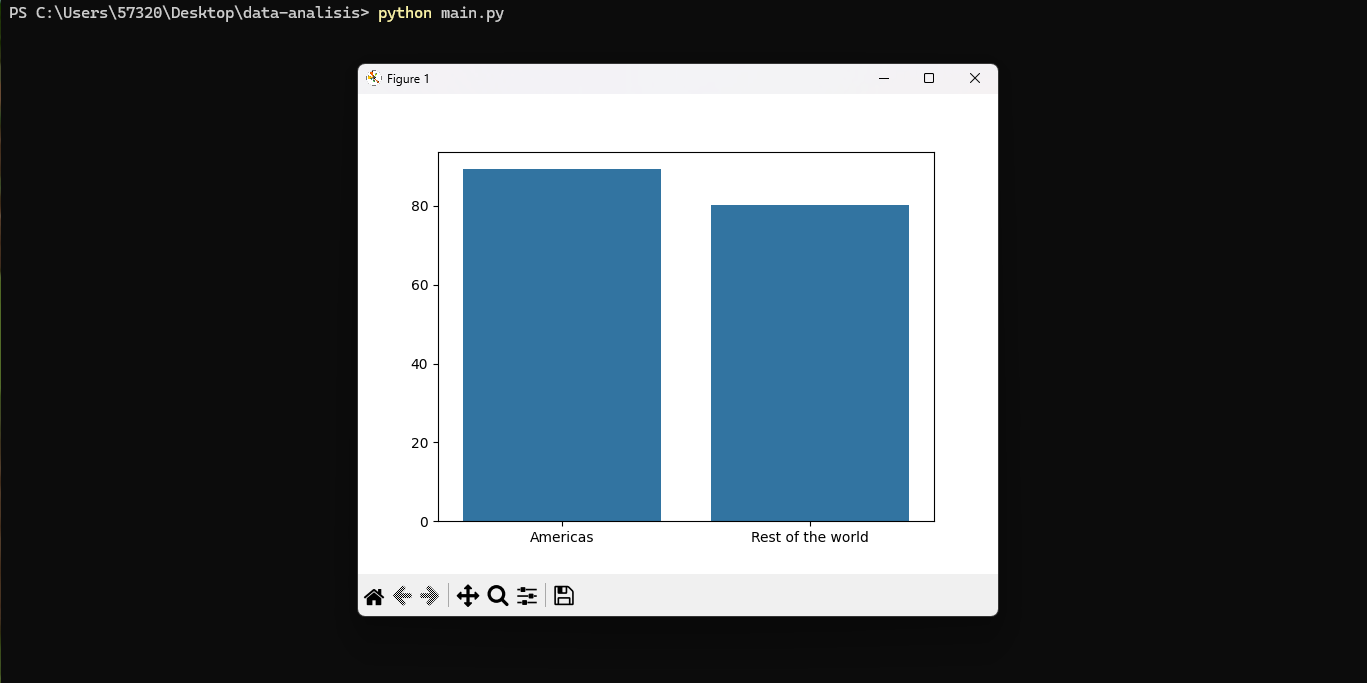
Otro gráfico de barras: Alfabetismo promedio entre Americas y el resto del mundo
#Pandas es la librería básica para la manipulación y análisis de datos
import pandas as pd
#Numpy es la biblioteca para crear vectores y matrices, además de un conjunto grande de funciones matemáticas
import numpy as np
#Seaborn es una librería que usamos para graficar
import seaborn as sns
#Statsmodels es la biblioteca para realizar modelos
#import statsmodels.formula.api as smf
# Importamos matplotlib.pyplot para mostrar el gráfico
import matplotlib.pyplot as plt
# Extraemos la informacionn
df_nations = pd.read_csv("https://raw.githubusercontent.com/DireccionAcademicaADL/Nations-DB/main/nations.csv", encoding="ISO-8859-1")
# Borramos la columna innecesaria ["Unnamed: 0"]
df_nations.drop(columns=["Unnamed: 0"], inplace=True)
# Añadimos una nuevacolumna que calcule el nuevo monto de gdp actuales
df_nations["gdp_pesos2021"] = df_nations["gdp"]*850
# Añadimos una nueva columna que nos indique que paises estan sobre la media en emision de CO2
df_nations["co2_recodificada"] = np.where(df_nations["co2"]> df_nations["co2"].mean(), 1, 0)
# Otro gráfico de barras: Alfabetismo promedio entre Americas y el resto del mundo
# Filtrar los datos para las Americas y el resto del mundo
df_americas = df_nations[df_nations['region'] == 'Americas']
df_resto_mundo = df_nations[df_nations['region'] != 'Americas']
# Calcular el alfabetismo promedio para cada grupo
alfabetismo_promedio_americas = df_americas['literacy'].mean()
alfabetismo_promedio_resto_mundo = df_resto_mundo['literacy'].mean()
# Usamos seaborn para graficar el histograma el alfabetismo promedio para cada grupo
sns.barplot(x=['Americas', 'Rest of the world'], y=[alfabetismo_promedio_americas, alfabetismo_promedio_resto_mundo])
# Mostramos la ventana emergente con el histograma
plt.show()
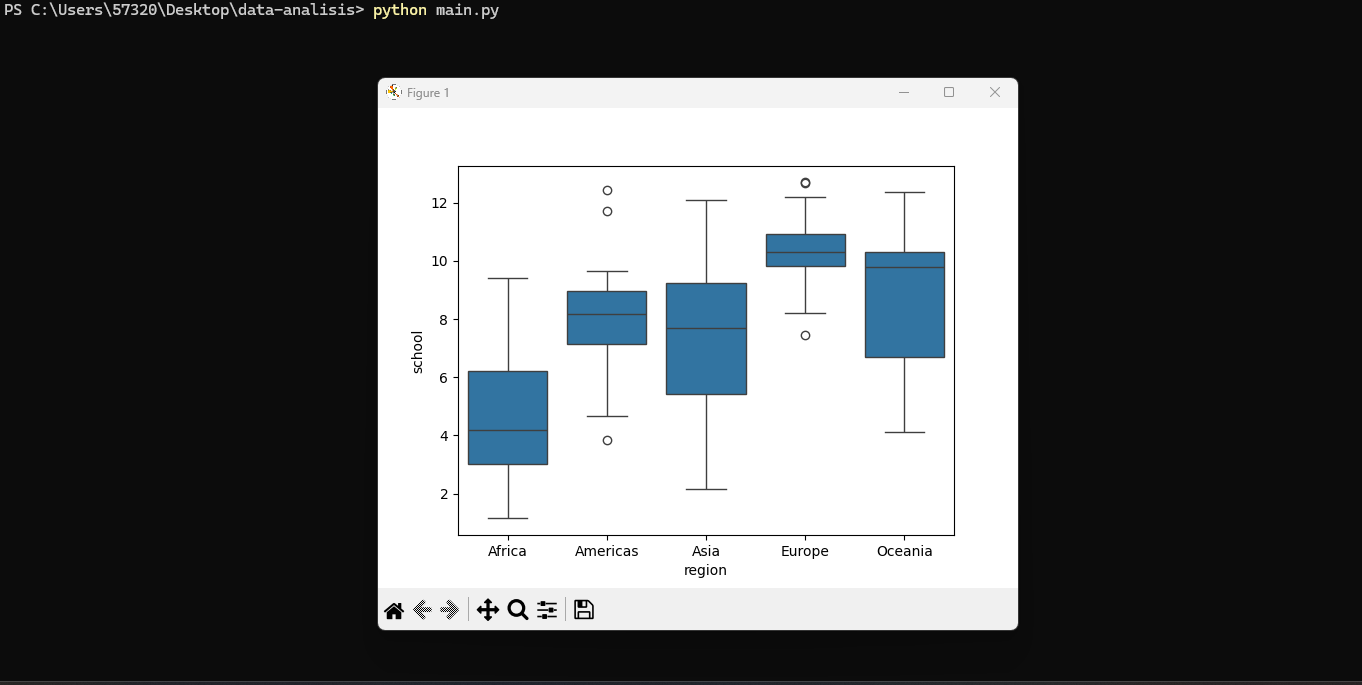
Ahora usando gráfico Boxplot para observar la distribución de la escolaridad por región
#Pandas es la librería básica para la manipulación y análisis de datos
import pandas as pd
#Numpy es la biblioteca para crear vectores y matrices, además de un conjunto grande de funciones matemáticas
import numpy as np
#Seaborn es una librería que usamos para graficar
import seaborn as sns
#Statsmodels es la biblioteca para realizar modelos
#import statsmodels.formula.api as smf
# Importamos matplotlib.pyplot para mostrar el gráfico
import matplotlib.pyplot as plt
# Extraemos la informacionn
df_nations = pd.read_csv("https://raw.githubusercontent.com/DireccionAcademicaADL/Nations-DB/main/nations.csv", encoding="ISO-8859-1")
# Borramos la columna innecesaria ["Unnamed: 0"]
df_nations.drop(columns=["Unnamed: 0"], inplace=True)
# Añadimos una nuevacolumna que calcule el nuevo monto de gdp actuales
df_nations["gdp_pesos2021"] = df_nations["gdp"]*850
# Añadimos una nueva columna que nos indique que paises estan sobre la media en emision de CO2
df_nations["co2_recodificada"] = np.where(df_nations["co2"]> df_nations["co2"].mean(), 1, 0)
# Ahora usando gráfico Boxplot para observar la distribución de la escolaridad por región
sns.boxplot(x=df_nations["region"], y=df_nations["school"])
# Mostramos la ventana emergente con el histograma
plt.show()
Otra forma de observar la información es a traves de los diagramas de dispersión, pero para usar estos necesitamos eliminar datos perdidos en el dataset.
#Pandas es la librería básica para la manipulación y análisis de datos
import pandas as pd
#Numpy es la biblioteca para crear vectores y matrices, además de un conjunto grande de funciones matemáticas
import numpy as np
#Seaborn es una librería que usamos para graficar
import seaborn as sns
#Statsmodels es la biblioteca para realizar modelos
#import statsmodels.formula.api as smf
# Importamos matplotlib.pyplot para mostrar el gráfico
import matplotlib.pyplot as plt
# Extraemos la informacionn
df_nations = pd.read_csv("https://raw.githubusercontent.com/DireccionAcademicaADL/Nations-DB/main/nations.csv", encoding="ISO-8859-1")
# Borramos la columna innecesaria ["Unnamed: 0"]
df_nations.drop(columns=["Unnamed: 0"], inplace=True)
# Añadimos una nuevacolumna que calcule el nuevo monto de gdp actuales
df_nations["gdp_pesos2021"] = df_nations["gdp"]*850
# Añadimos una nueva columna que nos indique que paises estan sobre la media en emision de CO2
df_nations["co2_recodificada"] = np.where(df_nations["co2"]> df_nations["co2"].mean(), 1, 0)
# Otra forma de observar la información es a traves de los diagramas de dispersión, pero para usar estos necesitamos eliminar datos perdidos en el dataset.
df_limpia = df_nations.dropna()
# Luego que tenemos los datos sin datos perdidos, procedemos a graficar en un grafico de dispersion
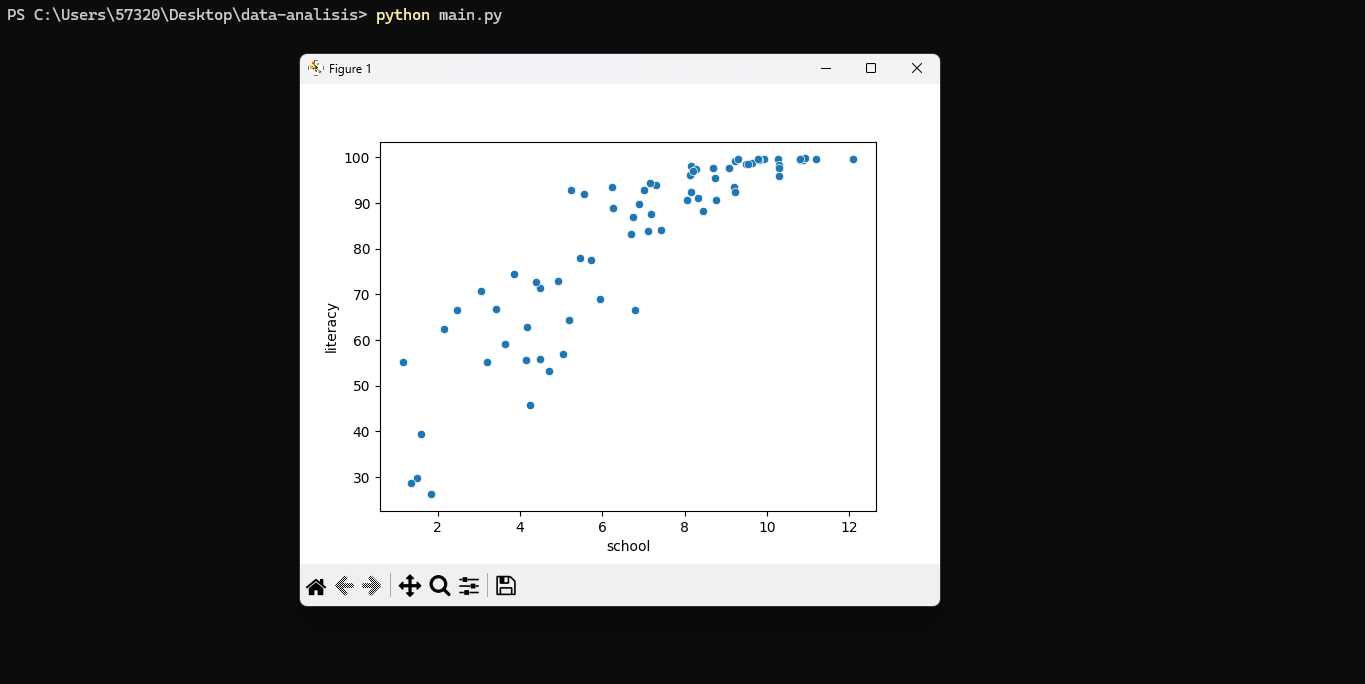
sns.scatterplot(x=df_limpia["school"], y=df_limpia["literacy"])
plt.show()
El último tipo de gráfico que revisaremos en este taller, corresponde al mapa de calor o heatmap. Este tipo de gráfico es una representación visual de los datos en que se muestra concentración o intensidad.
En este caso lo utilizaremos para buscar correlación entre las distintas variables de nuestro dataset.
¿Qué es correlación?
Correlación es una medida estadística que expresa hasta qué punto dos variables están relacionadas linealmente. Es una herramienta común para describir relaciones simples sin hacer afirmaciones sobre causa y efecto.
#Pandas es la librería básica para la manipulación y análisis de datos
import pandas as pd
#Numpy es la biblioteca para crear vectores y matrices, además de un conjunto grande de funciones matemáticas
import numpy as np
#Seaborn es una librería que usamos para graficar
import seaborn as sns
#Statsmodels es la biblioteca para realizar modelos
#import statsmodels.formula.api as smf
# Importamos matplotlib.pyplot para mostrar el gráfico
import matplotlib.pyplot as plt
# Extraemos la informacionn
df_nations = pd.read_csv("https://raw.githubusercontent.com/DireccionAcademicaADL/Nations-DB/main/nations.csv", encoding="ISO-8859-1")
# Borramos la columna innecesaria ["Unnamed: 0"]
df_nations.drop(columns=["Unnamed: 0"], inplace=True)
# Añadimos una nuevacolumna que calcule el nuevo monto de gdp actuales
df_nations["gdp_pesos2021"] = df_nations["gdp"]*850
# Añadimos una nueva columna que nos indique que paises estan sobre la media en emision de CO2
df_nations["co2_recodificada"] = np.where(df_nations["co2"]> df_nations["co2"].mean(), 1, 0)
# Seleccionamos solo las columnas numéricas para calcular la correlación
numeric_columns = df_nations.select_dtypes(include=np.number)
# Calculamos la correlación entre las columnas numéricas
corr = numeric_columns.corr()
# Creamos un gráfico de calor con la matriz de correlación
sns.heatmap(corr, annot=True, cmap='Greens')
plt.title('Matriz de Correlación')
plt.show()
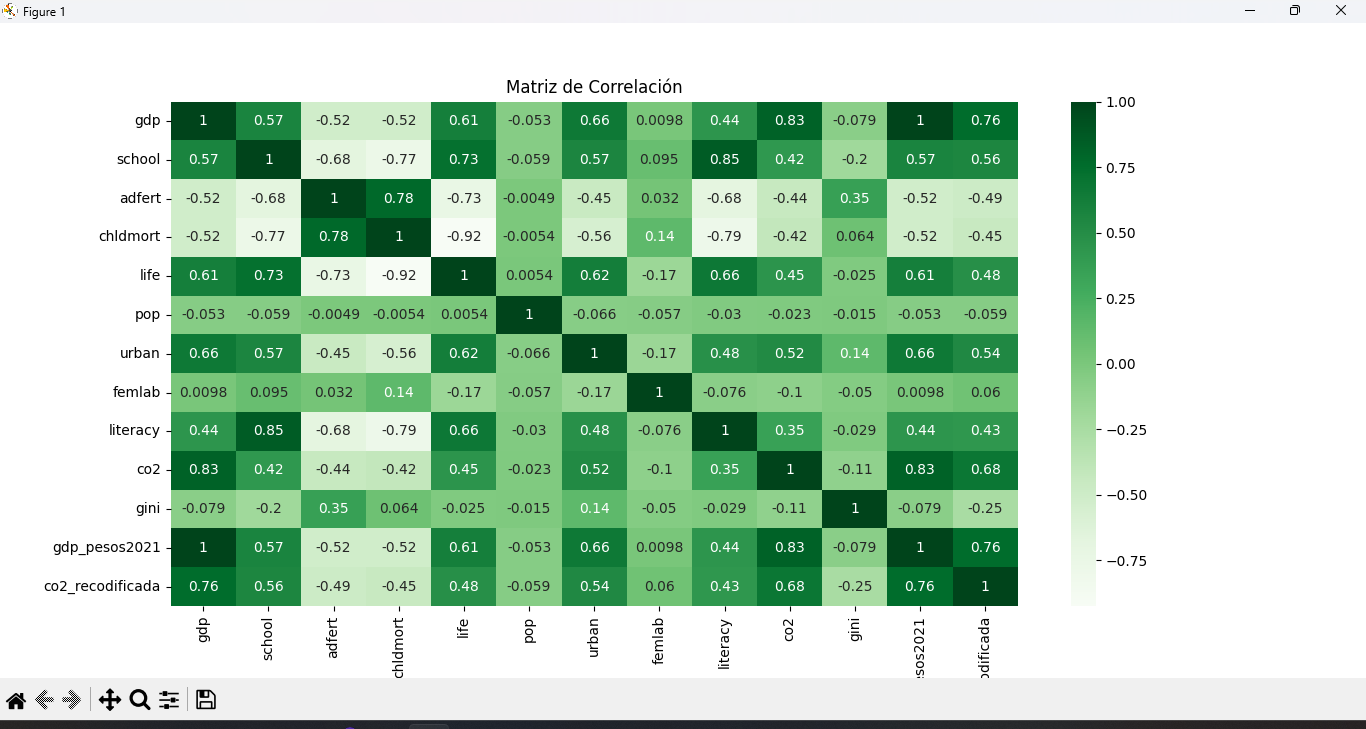
Dentro de las principales correlaciones existentes, nos encontramos con la correlación positiva entre mortalidad infantil y tasa de fertilidad adolecente, también la correlación positiva entre el promedio de años de escolaridad y tasa de alfabetización. Correlación entre PIB per capita y porcentaje de población urbana.
Sección de modelación
La regresión lineal es un modelo matemático usado para aproximar la relación de dependencia entre una variable dependiente Y, m variables independientes Xi y un término aleatorio (de error) e.
$y_{i}=β_{0}+β_{1xi1}+…+β_{mxim}+ϵ{i}$
La principal motivación es mostrar cuánto de la variabilidad de la variable dependiente Y es explicado por la variabilidad de las variables independientes Xi.
Para trabajar el modelo de regresión lineal es fundamental usar datos limpios de valores perdidos, por lo que utilizaremos el dataset que llamamos data_limpia.
Y los pasos a seguir para implementar el modelo de regresión lineal más simple:
- Plantear el modelo con su formula
- Ajustar el modelo utilizando el método
.fit() - Mostrar los resultados del modelo
De esta podemos podemos responder preguntas como:
¿Cual es la relación CO2 y el GDP?
#Pandas es la librería básica para la manipulación y análisis de datos
import pandas as pd
#Numpy es la biblioteca para crear vectores y matrices, además de un conjunto grande de funciones matemáticas
import numpy as np
#Statsmodels es la biblioteca para realizar modelos
import statsmodels.formula.api as smf
# Extraemos la informacionn
df_nations = pd.read_csv("https://raw.githubusercontent.com/DireccionAcademicaADL/Nations-DB/main/nations.csv", encoding="ISO-8859-1")
# Borramos la columna innecesaria ["Unnamed: 0"]
df_nations.drop(columns=["Unnamed: 0"], inplace=True)
# Añadimos una nuevacolumna que calcule el nuevo monto de gdp actuales
df_nations["gdp_pesos2021"] = df_nations["gdp"]*850
# Añadimos una nueva columna que nos indique que paises estan sobre la media en emision de CO2
df_nations["co2_recodificada"] = np.where(df_nations["co2"]> df_nations["co2"].mean(), 1, 0)
# Creamos una tabla con data limpia
df_limpia = df_nations.dropna()
# Basados en esta nueva tabla realizamos la consulta
# Plantear el modelo con su formula
modelo1 = smf.ols("gdp ~ co2", data=df_limpia)
# Ajustar el modelo utilizando el método .fit()
modelo1 = modelo1.fit()
# Mostrar los resultados del modelo
print(modelo1.summary())
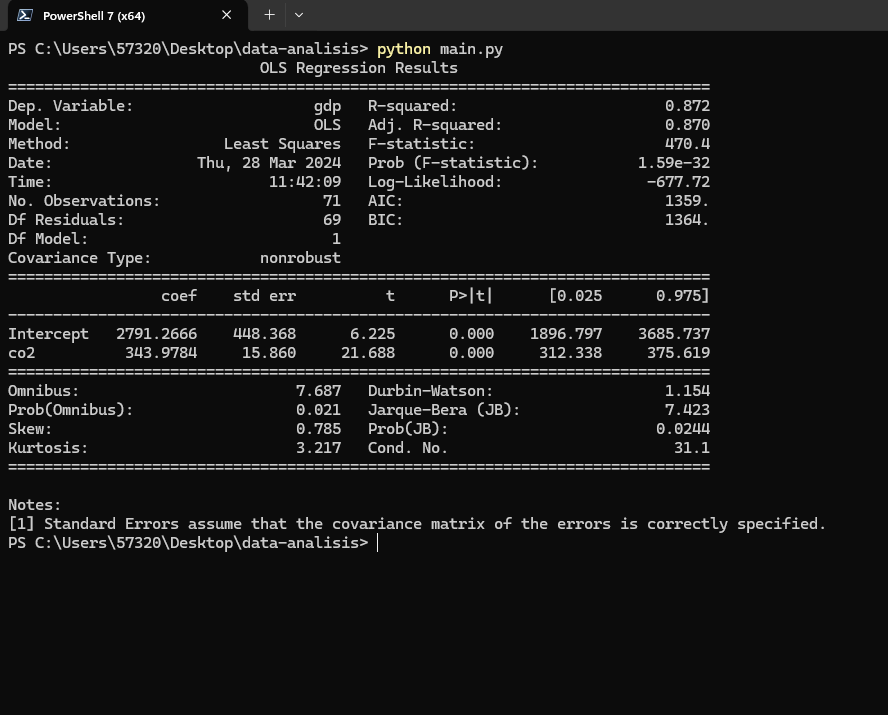
modelo de regresión lineal ordinaria (OLS) que examina la relación entre las emisiones de dióxido de carbono (CO2) y el Producto Interno Bruto (GDP). La variable dependiente (gdp) representa el GDP, mientras que la variable independiente (co2) representa las emisiones de CO2. El coeficiente de 343.9784 para la variable CO2 indica que, en promedio, un aumento de una unidad en las emisiones de CO2 está asociado con un aumento de 343.9784 unidades en el GDP, manteniendo todas las demás variables constantes. El valor p asociado con el coeficiente de CO2 es muy pequeño (p <0.001), lo que indica que la relación entre las emisiones de CO2 y el GDP es estadísticamente significativa. Además, el R-cuadrado de 0.872 indica que alrededor del 87.2% de la variabilidad en el GDP puede explicarse por las emisiones de CO2 en este modelo, lo que sugiere una relación bastante fuerte entre estas dos variables. En resumen, el modelo sugiere que existe una relación positiva y significativa entre las emisiones de CO2 y el GDP, lo que implica que un aumento en las emisiones de CO2 está asociado con un aumento en el GDP, en promedio. Sin embargo, es importante tener en cuenta que este modelo de regresión lineal no establece una relación causal definitiva entre estas variables, sino que proporciona una descripción estadística de su asociación.
A modo de ejercicio, te dejamos a continuación un modelo 2 para implementar, sigue el paso a paso y ejecuta el código por tu cuenta:
- Fórmula:
"gdp ~ chldmort + life + school + co2"y data utilizada es “df_limpia”. - Ajustar el modelo con
fit() - Mostrar resultados
#Pandas es la librería básica para la manipulación y análisis de datos
import pandas as pd
#Numpy es la biblioteca para crear vectores y matrices, además de un conjunto grande de funciones matemáticas
import numpy as np
#Statsmodels es la biblioteca para realizar modelos
import statsmodels.formula.api as smf
# Extraemos la informacionn
df_nations = pd.read_csv("https://raw.githubusercontent.com/DireccionAcademicaADL/Nations-DB/main/nations.csv", encoding="ISO-8859-1")
# Borramos la columna innecesaria ["Unnamed: 0"]
df_nations.drop(columns=["Unnamed: 0"], inplace=True)
# Añadimos una nuevacolumna que calcule el nuevo monto de gdp actuales
df_nations["gdp_pesos2021"] = df_nations["gdp"]*850
# Añadimos una nueva columna que nos indique que paises estan sobre la media en emision de CO2
df_nations["co2_recodificada"] = np.where(df_nations["co2"]> df_nations["co2"].mean(), 1, 0)
# Creamos una tabla con data limpia
df_limpia = df_nations.dropna()
# Basados en esta nueva tabla realizamos la consulta
# Plantear el modelo con su formula
modelo1 = smf.ols("gdp ~ chldmort + life + school + co2", data=df_limpia)
# Ajustar el modelo utilizando el método .fit()
modelo1 = modelo1.fit()
# Mostrar los resultados del modelo
print(modelo1.summary())
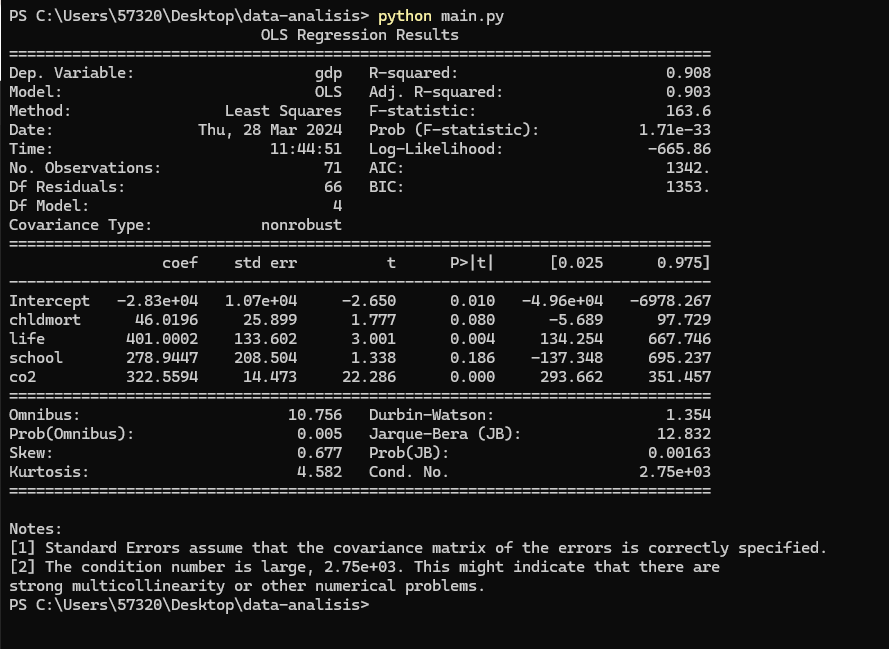
Este nuevo cuadro muestra los resultados de un modelo de regresión lineal múltiple que examina la relación entre el Producto Interno Bruto (GDP) y cuatro variables independientes: la tasa de mortalidad infantil (chldmort), la esperanza de vida (life), años de escolaridad (school), y las emisiones de dióxido de carbono (CO2). Los coeficientes asociados a cada variable indican la magnitud del cambio esperado en el GDP por cada unidad de cambio en la variable independiente correspondiente, manteniendo todas las demás variables constantes. Por ejemplo, el coeficiente de CO2 (322.5594) sugiere que un aumento de una unidad en las emisiones de CO2 está asociado, en promedio, con un aumento de 322.5594 unidades en el GDP, manteniendo constantes las otras variables. Los valores p asociados con cada coeficiente indican la significancia estadística de la relación entre cada variable y el GDP. En este caso, todas las variables, excepto “school”, tienen valores p significativos (p < 0.05), lo que sugiere que la mortalidad infantil, la esperanza de vida y las emisiones de CO2 están significativamente relacionadas con el GDP. El R-cuadrado ajustado de 0.903 indica que alrededor del 90.3% de la variabilidad en el GDP puede ser explicada por estas cuatro variables en conjunto, lo que sugiere que este modelo tiene un buen ajuste para explicar las fluctuaciones en el GDP. Sin embargo, es importante tener en cuenta las advertencias al final de la tabla, como la posible multicolinealidad entre las variables independientes.